Luigi's Mansion CS 175: Project in AI
Project Summary
We will be using OpenAI’s Gym toolkit to implement a Reinforcement Learning agent for Super Mario Bros. OpenAI provides a library called gym-super-mario-bros which allows users to emulate the original Super Mario Bros for the NES, giving us options to control Mario’s movement while also giving us feedback about the environment including things such as his X and Y position in the level and his accumulated score. We will be using these tools to train an agent that is capable of learning from the reward feedback and pathing towards finishing the first level of Super Mario Bros.
Approach
Our main algorithm to train an agent to play Super Mario Bros is Deep Q-Learning (DQN), which is Q-Learning with a neural network to approximate the optimal action-value function. This function, Q(s, a), represents the expected cumulative reward when taking an action a in state s and following the optimal policy after. (Luu)
Optimal Policy Equation: \(π^*(s)=argamaxQ^*(s,a)\)
The optimal policy π* is a function that maps each state to the action that results in the highest Q-value.
In DQN, the agent maintains a Q-table, which maps state-action pairs to expected future rewards. The Bellman Equation for Q-learning is used to update these values:
\[Q(s, a) ← Q(s, a) + α [r + γ max_{a'} Q(s’, a’) - Q(s, a)]\]r: immediate reward received after taking action a in state s
γ: a discount factor that balances immediate vs future rewards
s’: next state
a’: best action in s’
Q(s’, a’) : estimated by neural network
The Bellman Equation utilizes the Mean Squared Error (MSE) as the goal is to optimize the difference between target Q-values (r + $\gamma$ max Q(s’, a’)) and predicted Q-values (Q(s, a)). (Luu)
\[L(θ) = \mathbb{E}[(r + γ max_{a'} Q(s’, a’; θ^-)- Q(s, a;θ))^2]\]In the MSE, Θ− represents the target network and θ represents the parameters of the main Q-Network.
Training Process
State Representation & Action Space
The agent interacted with the Super Mario Bros environment through OpenAI Gym and Nes-Py. The environment provided state observations in the form of game frames, which are pre-processed and flattened into a vector representation before being inputted into the DQN.
To simplify the learning task, the agent interacts with the game using a limited action space (SIMPLE_MOVEMENT) derived from predefined movement sets (e.g. left, right, jump). For now, we are using the predefined environment function given by the environment. This function encourages progress through a level by providing positive reinforcement for moving to the right and surviving for a longer time. While there are negative rewards for failing, which is defined as dying or getting stuck.
Experience Replay & Target Network
Experience Replay
To prevent overfitting to recent experiences, we implemented an experience replay where past interactions are stored in a memory buffer of size 5,000 and sampled in mini-batches of size 32. Doing so allows the model to be more active in learning as it breaks the correlation between consecutive training samples.
Target Network
There is a target network that is updated periodically to compute more stable Q-value targets. This network should reduce divergence issues during training as it proves more stable Q-estimates.
Exploration vs Exploitation
For the agent to explore different strategies before committing to an optimal policy, we used the epsilon-greedy strategy. The agent initially selects random actions with a probability of 1.0 to encourage exploration. Over time, the probability decreases at .995 per episode until it reaches .01, ensuring the agent shifts towards exploiting learned strategies. Of course, this parameter of probability decreasing will be tested and played around more in the future to find what works best with our agent.
Neural Network
The neural network is optimized with the Adam optimizer with a learning rate of .001.
Input Layer: Process flattened game state
Hidden Layer: Size 128 -> Size 64 -> Action Space Size, using ReLu activation functions
Output Layer: Predicts Q-values for each action
Training Parameters
The agent is trained for three episodes, each running for a maximum of 10,000 steps. After training, the weights are saved for later use and video recordings of gameplay are saved for evaluation.
Parameter Values
| Parameter | Value |
|---|---|
| Discount Factor | 0.99 |
| Learning Rate (LR) | 0.001 |
| Batch Size | 32 |
| Memory Buffer Size | 5000 |
| Epsilon (start) | 1.0 |
| Epsilon (min) | 0.01 |
| Epsilon Decay | 0.995 |
| Training Episodes | 3 |
| Max Steps per Episode | 10,000 |
Evaluation
We are logging Mario’s reward progress to be viewed on Tensorboard to see if our agent is generally able to achieve a greater reward over time, similarly to Exercise 2. Additionally, we are generating videos periodically of Mario’s training episodes so we can visualize our agent’s progress and identify pitfalls. After matching rewards and videos together to subjectively review reward performances, we are able to determine the cause of falling rewards and situations where our algorithm / parameters are inefficient, and tweak it. For example, when Mario gets stuck at a pipe, his reward goes down due to his time being a negative component of his reward. As a result of seeing this correlation, we were able to change our parameters, increase exploration, and allow the agent to better discover a way to get over the pipes.
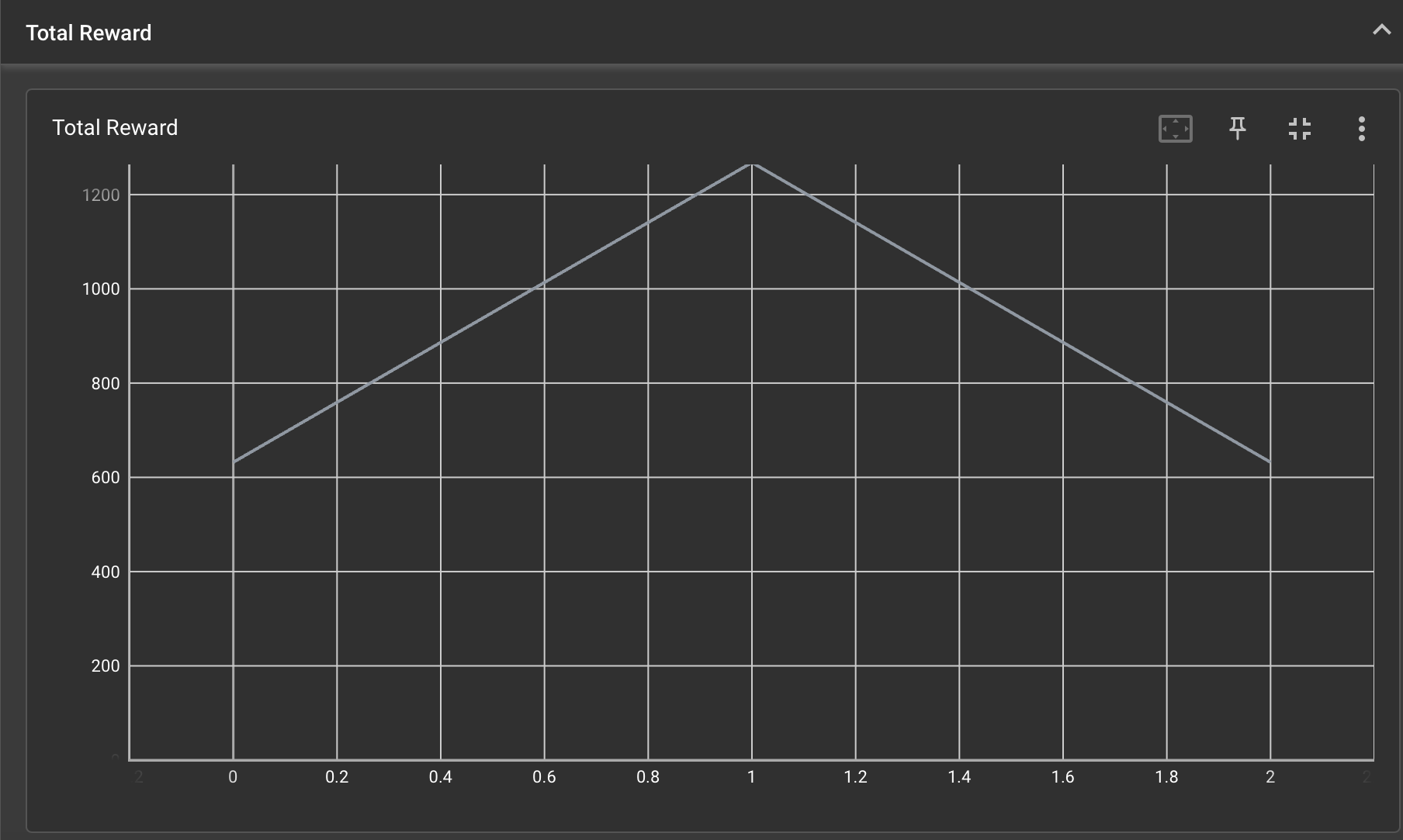
|
|
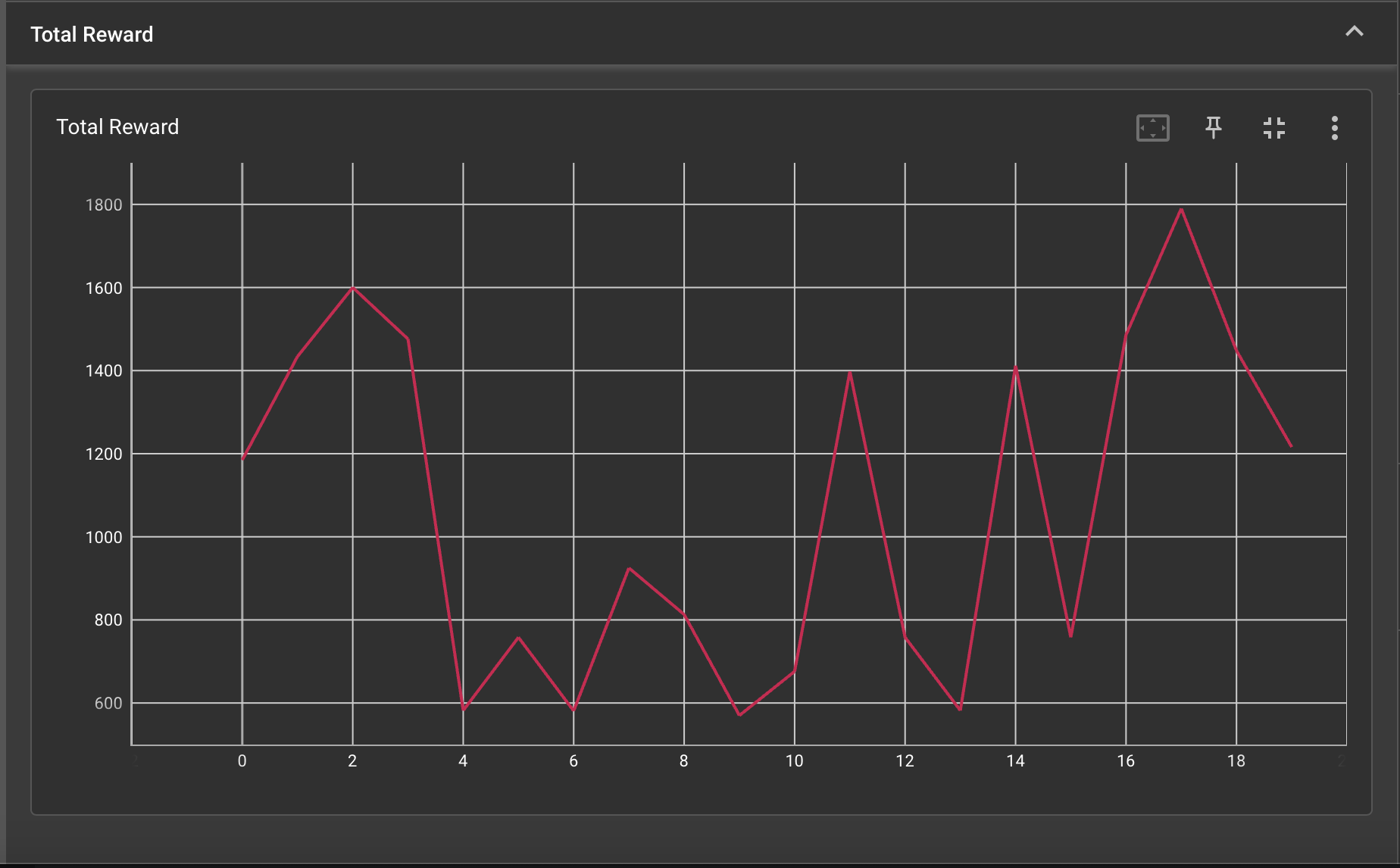
|
Remaining Goals and Challenges
Once we finish the current iteration of model that will finish the level, we want to add scene understanding to the model so it can more appropiately react to obstacles, change the reward function with custom information/elements, and potentially try a custom environment to test our model in a less controlled/unbiased environment. Currently, our model is doing the most simple task of completing through a level without advanced movement, vectoring, and other tricks. We can train our agent to be more optimal with it movement, more optimal with its time, or more optimal with its score. We anticipate that we will continue to struggle with matching package versions and recreating environments for each person to individually run. We will try packaging our enviornments and being cleaner with our package managers in order to keep the code and agent runnable for each member.
Resources Used
Some of the resources we used include official documentation from OpenAI on their Gym environment as well as various random StackOverflow pages from other users who have run into similar issues as us.
- https://pypi.org/project/gym-super-mario-bros/
- https://www.gymlibrary.dev/index.html
- https://stackoverflow.com/search?q=gym+Super+Mario+bros&s=40640cc8-8588-47e6-8b29-9e3c8d397d5b
Luu, Q. T. (2023, April 10). Q-Learning vs. Deep Q-Learning vs. Deep Q-Network | Baeldung on Computer Science. www.baeldung.com. https://www.baeldung.com/cs/q-learning-vs-deep-q-learning-vs-deep-q-network